Rational Trees and Binary Partitions
Peter Luschny, March 2010
Contents |
::: Stern's diatomic array revisited :::
Richard Stanley recently asked on MathOverflow (the question is now a community wiki):
I am interested
in theorems with unexpected conclusions. [...]
My favorite is the following. Let f(n) be the number of ways to write the nonnegative
integer n as a sum of powers of 2, if no power of 2 can be used more than twice.
For instance, f(6) = 3 since we can write 6 as 4 + 2 = 4 + 1 + 1 = 2 + 2 + 1 + 1.
We have
(f(0), f(1), ...) = (1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5, 3, 4, ...).
The conclusion is that the numbers f(n) / f(n + 1) run through all the reduced positive
rational numbers exactly once each.
Looking the sequence up I found the following remark by Igor Urbiha:
A002487 := proc(m) local a, b, n; a := 1; b := 0; n := m; while n>0 do if type(n, odd) then b := a+b else a := a+b end if; n := floor(n/2); end do; b; end proc:
Program adapted from E. Dijkstra, Selected Writings on Computing, Springer, 1982, p. 232. I pondered on a slight generalization of this function:
SternsDiatomic := proc(m, i, j) local a, b, n; a := i; b := j; n := m; while n > 0 do if n mod 2 = 1 then b := a + b else a := a + b fi; n := iquo(n, 2); od; [a, b] end:
Here are the six most simple variants it generates:
seq(op(1,SternsDiatomic(i,1,0)),i = 0..32);
1, 1, 1, 1, 1, 2, 1, 1, 1, 3, 2, 3, 1, 2, 1, 1, 1, 4, 3, 5, 2, 5,
seq(op(2,SternsDiatomic(i,1,0)),i = 0..32);
0, 1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5, 3, 4, 1, 5, 4, 7, 3, 8,
seq(op(1,SternsDiatomic(i,0,1)),i = 0..32);
0, 0, 1, 0, 2, 1, 1, 0, 3, 2, 3, 1, 2, 1, 1, 0, 4, 3, 5, 2, 5, 3,
seq(op(2,SternsDiatomic(i,0,1)),i = 0..32);
1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5, 3, 4, 1, 5, 4, 7, 3, 8, 5,
seq(op(1,SternsDiatomic(i,1,1)),i = 0..32);
1, 1, 2, 1, 3, 3, 2, 1, 4, 5, 5, 4, 3, 3, 2, 1, 5, 7, 8, 7, 7, 8,
seq(op(2,SternsDiatomic(i,1,1)),i = 0..32);
1, 2, 3, 3, 4, 5, 5, 4, 5, 7, 8, 7, 7, 8, 7, 5, 6, 9, 11, 10, 11,
The parameters (i, j, op(k)) map as follows to sequences in OEIS.
| Interpretations of the generated sequences | |||||
| (1,0,1) | A070879 mod a leading 1 | Stern's diatomic array read by rows | |||
| (1,0,2) | A002487 | Stern's diatomic series | |||
| (0,1,1) | missing | ? | |||
| (0,1,2) | A002487 mod a missing 0 | Stern's diatomic series | |||
| (1,1,1) | A047679 mod a leading 1 | Denominator in full Stern-Brocot tree | |||
| (1,1,2) | A007306 mod a missing 1 | Denominators of Farey tree fractions | |||
A comment in A002487 observes: "Since A007306(n) = a(2n+1), this program can be adapted for A007306 by replacing b := 0 by b := 1." Indeed, this is the case (1,1,2) in our setup. At least we found a simple way to compute A070879 and A047679. (C. f. for example the complicated way A047679 is computed with Mathematica in the comments of A007305). Now the question is: Is there an interpretation of the missing case (0,1,1) which fits into the general picture?
seq(SternsDiatomic(i,`*`,`#`),i = 0..20); [1* + 0#, 0* + 1#], [1* + 0#, 1* + 1#], [1* + 1#, 1* + 2#], [1* + 0#, 2* + 1#], [1* + 2#, 1* + 3#], [2* + 1#, 3* + 2#], [1* + 1#, 2* + 3#], [1* + 0#, 3* + 1#], [1* + 3#, 1* + 4#], [3* + 2#, 4* + 3#], [2* + 3#, 3* + 5#], [3* + 1#, 5* + 2#], [1* + 2#, 2* + 5#], [2* + 1#, 5* + 3#], [1* + 1#, 3* + 4#], [1* + 0#, 4* + 1#], [1* + 4#, 1* + 5#], [4* + 3#, 5* + 4#], [3* + 5#, 4* + 7#], [5* + 2#, 7* + 3#], [2* + 5#, 3* + 8#],
Stern's diatomic array is here a sequence of pairs relative to two symbols (here `*` and `#`) and one operation (here +). The choice of 0 and 1 for the symbols gives a nice result; however this choice conceals completely the structure of the computation. (Dijkstra named his function fusc because it obfuscates so much.)
The missing 'diatomic array' read by rows:
| ∑ | n\k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 0 | 0 | 0 | |||||||||||||||
| 1 | 1 | 0 | 1 | ||||||||||||||
| 4 | 2 | 0 | 2 | 1 | 1 | ||||||||||||
| 13 | 3 | 0 | 3 | 2 | 3 | 1 | 2 | 1 | 1 | ||||||||
| 40 | 4 | 0 | 4 | 3 | 5 | 2 | 5 | 3 | 4 | 1 | 3 | 2 | 3 | 1 | 2 | 1 | 1 |
The sum of the n-th row is (3n − 1) / 2, row n has length 2n and each column is an arithmetic progression.
If we name the function lusc (which is a malapropism for Dijkstra's fusc), and let Maple compute
seq(lusc(k+1)/lusc(k),k=2..2); seq(lusc(k+1)/lusc(k),k=4..5); seq(lusc(k+1)/lusc(k),k=8..11); seq(lusc(k+1)/lusc(k),k=2^i..(2^i+2^(i-1)-1);
we run through all the reduced nonnegative rational numbers exactly once.
0/1 1/2, 1/1 2/3, 3/2, 1/3, 2/1 3/4, 5/3, 2/5, 5/2, 3/5, 4/3, 1/4, 3/1 4/5,7/4,3/7,8/3,5/8,7/5,2/7,7/2,5/7,8/5,3/8,7/3,4/7,5/4,1/5,4/1
So we observe that the diatomic array displays more than we actually need. What we need is the lusc sequence. So let us summarize our findings with some Maple code.
The lusc function:
lusc := proc(m) local a, b, n; a := 0; b := 1; n := m; while n > 0 do if n mod 2 = 1 then b := a + b else a := a + b fi; n := iquo(n, 2); od; a end:
The lusc sequence:
luscSeq := proc(n) local i, k; for i from 1 to n do print(seq(lusc(k),k = 2^i..2^i+2^(i-1))) od end:
The lusc tree:
luscTree := proc(n) local i, k; for i from 0 to n do print(seq(lusc(k + 1)/lusc(k), k = 2^i..2^i+2^(i-1)-1)) od end:
The lusc sequence starts
1, 0, 2, 1, 1, 3, 2, 3, 1, 2, 4, 3, 5, 2, 5, 3, 4, 1, 3, 5, 4, 7, 3, 8, 5, 7, 2, 7, 5, 8, 3, 7, 4, 5, 1, 4,
It is convenient to displayed this sequence as a triangle:
1, 0
2, 1, 1
3, 2, 3, 1, 2
4, 3, 5, 2, 5, 3, 4, 1, 3
5, 4, 7, 3, 8, 5, 7, 2, 7, 5, 8, 3, 7, 4, 5, 1, 4
Reading the rows from right to left an alternative and perhaps even more natural way to write the lusc sequence is:
0, 1, 1, 1, 2, 2, 1, 3, 2, 3, 3, 1, 4, 3, 5, 2, 5, 3, 4, 4, 1, 5, 4, 7, 3, 8, 5, 7, 2, 7, 5, 8, 3, 7, 4, 5
For the purpose of easy comparison: Stern's diatomic sequence starts
0, 1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5, 3, 4, 1, 5 4, 7, 3, 8, 5, 7, 2, 7, 5, 8, 3, 7, 4, 5, 1, 6, 5, 9
::: Rational Trees :::
Anyway, we entered the world of trees now. There is a special page in this Encyclopedia, The_Stern-Brocot_or_Farey_Tree, with hints to many associated sequences. On Wikipedia there is an entry for the SB-tree and the CW-tree.
Let us compare the trees. Whereas the Stern-Brocot tree runs through the reduced positive rational numbers our tree runs through the nonnegative rational numbers. Though it might be natural to omit the zero from the naturals it is not rational to omit the zero from the rationals.
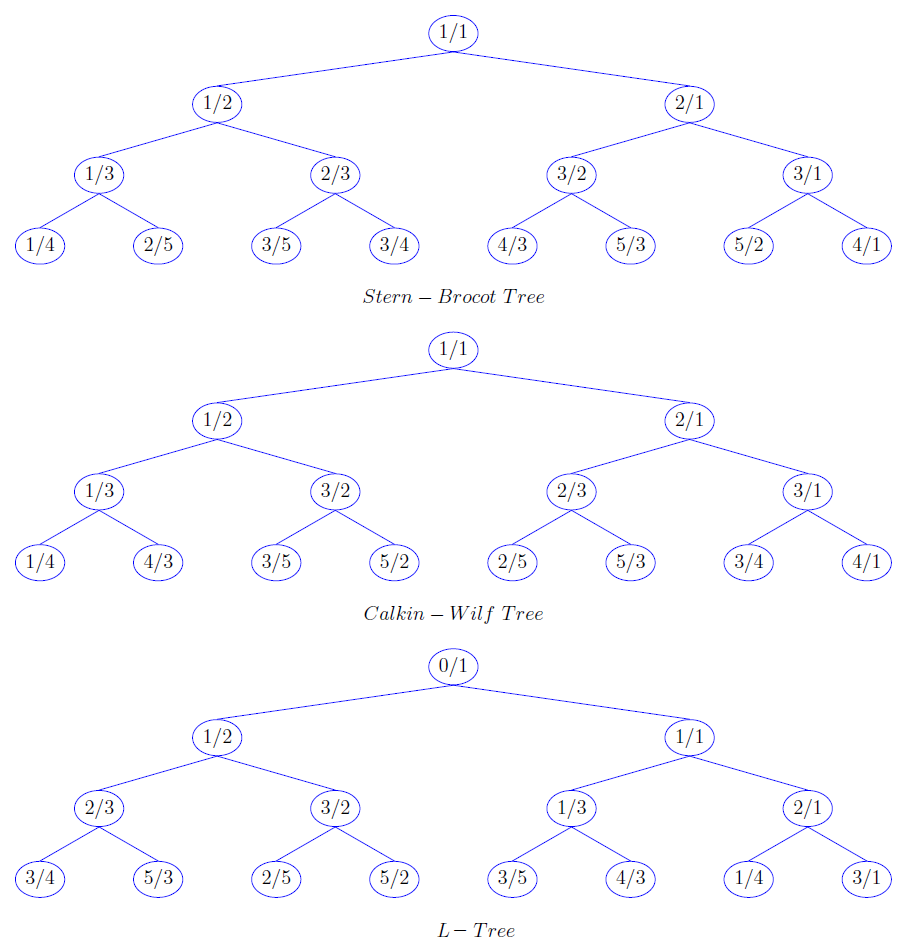
Trees enumerating the reduced rationals.
Given a reduced fraction, where is it located in the CW-tree? The next function gives an answer by listing the (unique) path from the root of the tree to the node containing the fraction.
FractionToPathInCWtree := proc(a, b) local path, Rec; Rec := proc(a, b) if a = 1 and b = 1 then path := "@".path; elif a < b then path := "L".path; Rec(a, b-a); elif a > b then path := "R".path; Rec(a-b, b); else path := "?" fi end; # not relatively prime path := ""; Rec(a, b) end:
(Here "L"."ABC.." -> "LABC.." denotes the concatenation operation.) Observe that the algorithm of Nicomachus is build in this little function. This opens doors to some amazing new insights ...
Conversely, given a path in the tree starting at the root, at what fraction will it end?
PathInCWtreeToFraction := proc(path) local a, b, x;
for x in path do
if x = "?" then RETURN(-1) # invalid path
elif x = "@" then a := 1; b := 1; # root
elif x = "L" then b := b + a
else a := a + b fi;
od; a / b end:
For example FractionToPathInCWtree(3,4) will output "@RRL", which says: "Start
at the root @, step right, step right, step left. The node you reached contains
3/4."
Conversely PathInCWtreeToFraction("@RRL") will output 3/4.
Next we want to map the CW-tree to the L-tree in a one-to-one manner. A tree can be enumerated in two fundamental ways.
The 'western style' enumeration
1
2 → 3
4 → 5 → 6 → 7
. . .
and the 'eastern style' enumeration
0
2 ← 1
6 ← 5 ← 4 ← 3
. . .
The CW-tree is enumerated in eastern style, the L-tree in western style. Assume
the fraction a/b located at the right diagonal (the case b = 1) in one tree then
the same fraction is located in the other tree also at the right diagonal, just
one line higher or lower, depending on the direction of view. For all other fractions
the situation is even simpler:
If a / b is on position k in the CW-tree
(eastern style enumerated) then it is also on position k in the L-tree (western
style enumerated).
This one-to-one correspondence shows that every positive rational occurs once and only once in the L-tree because we know that the CW-tree has this property.
Let us illustrate this bijection.
CWTree := proc(n) local i, R; for i from 0 to n-1 do R := 2^i..2^(i+1)-1: print(seq([3*2^i-k-2, fusc(k) / fusc(k+1)], k = R)); od end:
[0, 1 ] 'eastern style': [position, value] [2, 1/2],[1, 2 ] [6, 1/3],[5, 3/2],[4, 2/3],[3, 3 ] [14,1/4],[13,4/3],[12,3/5],[11,5/2],[10,2/5],[9,5/3],[8,3/4],[7,4]
LTree := proc(n) local i, R; for i from 1 to n do R := 2^i..3*2^(i-1)-1: print(seq([k-2^(i-1), lusc(k+1) / lusc(k)], k = R)); od end:
[1,0 ] 'western style': [position, value] [2,1/2],[3,1 ] [4,2/3],[5,3/2],[6, 1/3],[7, 2 ] [8,3/4],[9,5/3],[10,2/5],[11,5/2],[12,3/5],[13,4/3],[14,1/4],[15,3]
Another useful tool to enumerate the L-tree (in fact it is the basic recurrence of the lusc function) is to give the children of a vertex by the vertex number.
ChildrenByVertexNumber := proc(n) local K;
K := 2^simplify(floor(log[2](n))) + n; # ignore 'simplify'
printf("Vertex %2d: The children of %4a are %4a and %4a.\n",
n,lusc(K+1)/lusc(K),lusc(2*K+1)/lusc(2*K),lusc(2*K+2)/lusc(2*K+1))
end:
seq(ChildrenByVertexNumber(i),i = 1..15);
Vertex 1: The children of 0 are 1/2 and 1.
Vertex 2: The children of 1/2 are 2/3 and 3/2.
Vertex 3: The children of 1 are 1/3 and 2.
Vertex 4: The children of 2/3 are 3/4 and 5/3.
Vertex 5: The children of 3/2 are 2/5 and 5/2.
...
A pretty pattern emerges if we plot the trees by the vertex numbers, the L-tree (red) and the CW-tree (black) on the same canvas.
LTreeByVertexNumber := proc(n) local K;
K := 2^simplify(floor(log[2](n)))+n; lusc(K+1) / lusc(K) end:
CWTreeByVertexNumber := proc(n) fusc(n) / fusc(n+1) end:
R:= 1..511: pplot := (f, colour) ->
pointplot({seq([k, f(k)], k = R)}, color = colour, thickness = 3):
A := pplot(LTreeByVertexNumber, red): B := pplot(CWTreeByVertexNumber, black):
C := plot(log[2](y),y = R, color = blue): display([A, B, C]);

The transition from the CW-tree to the L-tree can be viewed as adding the zero to the CW-tree. It transforms Hilbert's way to manage his hotel when a new guest arrives to a way to manage an infinite tree in such a situation (pushing the root instead of adding a leaf). We also observed some kind of duality in this process related to the order of the enumeration ...
It should be noted that Calkin and Wilf associate their tree with the following enumeration of the rationals
(CW) 1/1, 1/2, 2/1, 1/3, 3/2, 2/3, 3/1, 1/4, 4/3, 3/5, 5/2, 2/5, 5/3, ...
whereas the enumeration we associated with the CW-tree is by reading the rows in the tree from the right to the left
(CW*) 1/1, 2/1, 1/2, 3/1, 2/3, 3/2, 1/3, 4/1, 3/4, 5/3, 2/5, 5/2, 3/5, ...
More precisely: starting with a rewrite of Stern's diatomic array as a sequence of pairs we arrived at a pair of enumerations of the rationals, one being (CW*) and the other
(L) 0, 1/2, 1, 2/3, 3/2, 1/3, 2, 3/4, 5/3, 2/5, 5/2, 3/5, 4/3, 1/4, 3, ...
Now it's time for the magical mystery tour.
0; do magic(%) od;
I invite the reader to execute the above one line Maple code (and quickly pressing the stop button). All you have to do beforehand is to set
magic := x -> 1/(1+floor(x)-frac(x)):
For those unfamiliar with Maple: % is the ditto operator, referring to the previously computed expression. So the first expression is '0', the next expression is magic(0), the next magic(magic(0)), etc. (Does this not remind us of the way John von Neumann generated his ordinal numbers?) Then a miracle occurs:
0, 1, 1/2, 2, 1/3, 3/2, 2/3, 3, 1/4, 4/3, 3/5, 5/2, 2/5, 5/3, 3/4, 4,...
It is the L-tree in eastern style enumeration. (The interested reader might whish to look into Aigner and Ziegler, Proofs from THE BOOK, third ed..)
~ ~ ~
The same enumeration can also be computed by a generalization of Dijkstra's fusc function.
LTreeEastEnum := proc(m) local a, b, A, B, n; n := m; a, b, A, B := 1, 0, 1, 0; while n > 0 do a + b, A + B; if n mod 2 = 1 then b, A := % else a, B := % fi; n := iquo(n,2); od; b / A end:
We will come back to generalizations of the fusc function after the next chapter.
::: Binary Partitions :::
The story could end here. However, this would miss the point Richard Stanley made in his question on MathOverflow. Stanley emphasized the surprising connection of the enumeration of the rationals with a special binary partition function which Calkin and Wilf call the number b(n) of hyperbinary representations of an integer n.
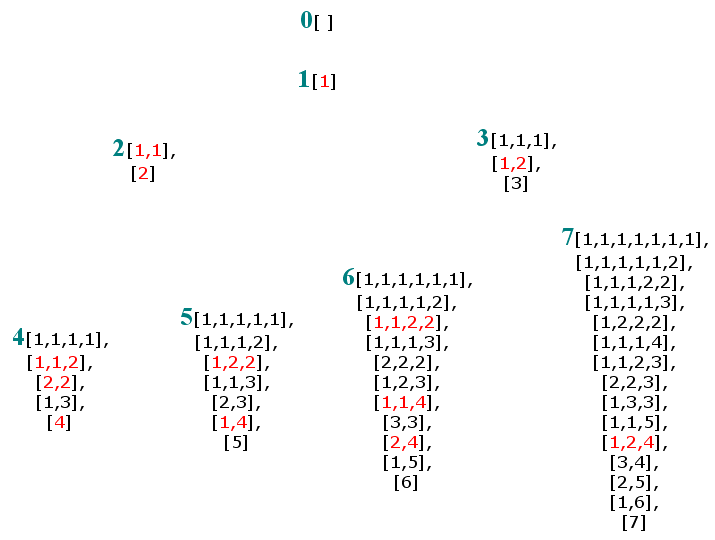
b(n) is the number of ways of writing the integer n as a sum of powers of 2, each power being used at most twice. For instance, we can write 8 = 1 + 1 + 2 + 4 = 2 + 2 + 4 = 4 + 4 = 8, so b(8) = 4. Calkin and Wilf showed, giving reference to a paper of Bruce Reznick, that b(n) = fusc(n+1).
The question now is: Is there a partition function which is related to the lusc function in some similar way?
As we already noticed (see the ChildrenByVertexNumber function above) — and which can be easily proven from the position of the fractions in the tree — that the lusc function obeys the recurrence equations
β(2n + 1) = β(n) and β(2n) = β(n − 1) + β(n) + [n = 2k]
valid for n = 1, 2, 3, ..., together with β(0) = 0. [n = 2k] is 1 if n is a power of 2, 0 otherwise (Iverson bracket). The second equation can also be stated equivalently in the computational simpler form β(2n) = max(β(n − 1), 1) + β(n).
We could transfer the interpretation of counting the hyperbinary representations of n from the CW-tree to the L-tree.
HyperbinsPerLusc := proc(n) local N, L, H;
N := BinaryFlip(n);
L := lusc(n); # L := fusc(N);
if N > 1 then N := N - 1 fi;
H := HyperbinaryRepresentations(N);
printf("%s%2d%s%2d %s %2d%s%a\n",
"lusc(",n,") = ", L, " -> ", N, ". ", H) end:
Let us look closer at the binary structure of the duality which we encountered in the formula relating the lusc with the fusc function. The relation is very simple. Let BinaryFlip(n) denote the base 2 representation of n with all the bits flipped.
BinaryFlip := proc(n) local i, B; B := convert(n, base, 2); add((1-B[i])*2^(i-1), i=1..nops(B)) end:
Then lusc(n) = fusc(BinaryFlip(n)) (n≥0). We also could have written this with Maple (which often has problems to simplify the obvious things automatically)
lusc(n) = fusc(simplify(2^(floor(log[2](n))+1))-n-1),
but this looks pretty uncool.
seq(HyperbinsPerLusc(i), i = 16..20 );
Read "→" as "is the number of hyperbinary representations of".
lusc(16) = 4 → 14. [[1, 1, 2, 2, 4, 4], [1, 1, 2, 2, 8], [1, 1, 4, 8], [2, 4, 8]]
lusc(17) = 3 → 13. [[1, 2, 2, 4, 4], [1, 2, 2, 8], [1, 4, 8]]
lusc(18) = 5 → 12. [[1, 1, 2, 4, 4], [2, 2, 4, 4], [1, 1, 2, 8], [2, 2, 8], [4,
8]]
lusc(19) = 2 → 11. [[1, 2, 4, 4], [1, 2, 8]]
lusc(20) = 5 → 10. [[1, 1, 2, 2, 4], [1, 1, 4, 4], [2, 4, 4], [1, 1, 8], [2, 8]]
However, this is not convincing. A better interpretation has to be found. Can we surprise Richard Stanley with another unexpected conclusion? What we need now is some kind of hyperbinaryflip ...
A binary partition of an integer n, n ≥ 0, is a partition of n which has only parts which are powers of 2. A superbinary partition is a binary partition with the property that the number of times equal parts appear are powers of 2.
The number of superbinary partitions can be computed recursively and agree with the values of [A086449] (see also the generating function given there by H. Wilf).
SuperBinary := proc(n) option remember; local IndexSet, k; IndexSet := proc(n) local i, I, z; i := iquo(n,2); I := i; i := i-1; z := 1; while 0 <= i do I := I,i; i := i-z; z := z+z od; I end: if n < 2 then 1 elif n mod 2 = 1 then SuperBinary(iquo(n,2)) else add(SuperBinary(k), k = IndexSet(n)) fi end:
However, not all superbinary partitions are created equal. Some are more binary than others. These are the superduperbinary partitions. Clearly [2] is a superduperbinary partition by default, called the BIN.
A superbinary partition is a superduperbinary partition if two conditions are satisfied:
- After repeatedly dividing the partition by 2 until all parts are ≤ 2, the
final partition is a power of BIN, which means is
BIN = [2] or BIN2 = [2,2] or BIN3 = [2,2,2] or .. etc.
- At any stage of this repeated reduction at most 2 singletons ('1'-parts) show up in the partition (which includes the start partition).
By 'dividing by 2' of a binary partition we understand the application of integer divide, thus for instance [1,2,4,8] / 2 = [0,1,2,4] = [1,2,4]. This is equivalent to saying "first remove the '1's and then divide the rest".
For example let us consider the superbinary partitions of 11.
[4, 4, 2, 1], [8, 2, 1] Dividing by 2 -> [2, 2, 1], [4, 1] Dividing by 2 -> [1, 1], BIN
Therefore only [8, 2, 1] is a superduperbinary partition of 11. Let's try another one, the superbinary partitions of 19.
[4,4,4,4,2,1], [8,4,4,2,1], [8,8,2,1], [16,2,1] Dividing by 2 -> [2,2,2,2,1], [4,2,2,1], [4,4,1], [8,1] Dividing by 2 -> [1,1,1,1] , [2,1,1] , BIN^2 , [4] Dividing by 2 -> - , - , - , BIN
We conclude that only [8, 8, 2, 1] and [16, 2, 1] are superduperbinary partitions of 19. With a little help from Maple checking is easier. The function below expects a superbinary partition as input and returns the partition if it is a superduperbinary partition or nothing otherwise.
SuperDuperBinaryFilter := proc(q) local p; p := q;
do if convert(p, set) = {2} then RETURN(q) fi;
if nops(select(x->x=1, p)) > 2 then RETURN(NULL) fi;
p := remove(x->x=1,p); if nops(p) = 0 then RETURN(NULL) fi;
p := p / 2; od end:
We can also generate the superduperbinary partitions of an integer n by recursion, as follows.
SuperDuperBinary := proc(n)
local h,B,H,C,i,BinaryFlip,Double;
BinaryFlip := proc(n) local i,B;
B := convert(n,base,2);
add((1-B[i])*2^(i-1),i=1..nops(B)) end:
Double := proc(W, T) local A,B,L; B := [];
for L in W do
A := 2*L;
if T = 1 then A := [op(A), 1] fi;
if T = 2 then A := [op(A), 1, 1] fi;
B := [op(B), A];
od; B end;
if n < 2 then RETURN([]) fi;
if n = 2 then RETURN([[2]]) fi;
h := iquo(n, 2);
if n mod 2 = 1 then
if BinaryFlip(n) = 0 then RETURN([]) fi;
H := SuperDuperBinary(h);
B := Double(H, 1);
else
H := SuperDuperBinary(h);
B := Double(H, 0);
H := SuperDuperBinary(h - 1);
C := Double(H, 2);
B := [op(B),op(C)];
if BinaryFlip(n) = n-1 then
B := [op(B),[seq(2,i=1..h)]] fi;
fi;
B end:
The prototype of a superbinary partition which is not a superduperbinary partition is [1,2,4,...,2k]. Though this partition looks very 'binary', such a partition can not be reduced (by repeated divisions by 2) to a power of BIN.
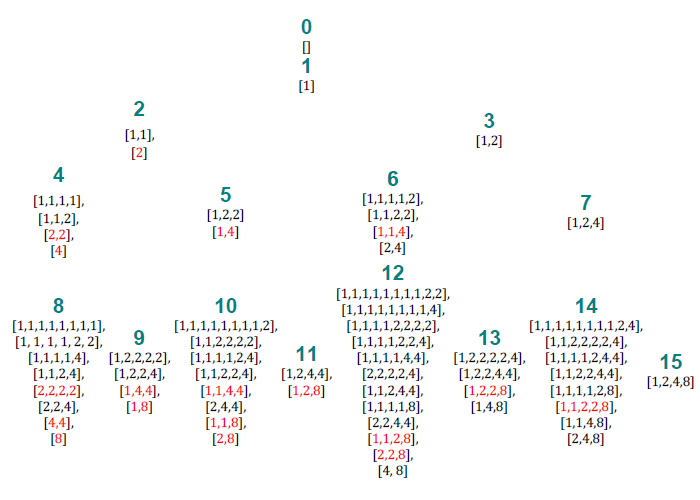
Theorem: The superduperbinary partitions of n are counted by the lusc function.
Proof: Let sdb stand for 'superduperbinary' and b(n) for the number of sdb partitions of n. We claim that b(n) = lusc(n) for all n ≥ 0.
As we have already seen (from the way the L-tree is build) that the lusc function obeys the recurrences
lusc(2n+1) = lusc(n) and lusc(2n) = lusc(n − 1) + lusc(n) + [n = 2k]
with lusc(0) = lusc(1) = 0. We will show that lusc(n) and b(n) satisfy the same recurrence formulas and take the same initial values, hence they agree on all nonnegative integers.
This is true for n = 0, 1 and suppose it is true for all integers 0, 1, ..., 2n.
-
Now b(2n + 1) = b(n), because if we are given a sdb partition of 2n + 1, the '1' must appear exactly once (more than two times is not allowed by the definition of sdb, and 2 times is not possible), hence by deleting this '1' and dividing by 2, we get a superbinary partition of n. This partition is also a sdb partition because the original partition and the divided one reduce to the same root which is a power of BIN by hypotheses.
Conversely, given a sdb partition of n, double each part and add a '1' to obtain a sdb partition of 2n + 1.
-
Assume now that n is not a power of 2. Then b(2n) = b(n − 1) + b(n). A sdb partition p of 2n might have either two 1's or no 1's in it.
*If p has no 1's, then we divide by 2 to get an sdb partition of n.
*If p has two 1's, then by deleting them and dividing by 2 we obtain a sdb partition of n − 1.Conversely, if p is a sdb partition of n then double each part, if p is a sdb partition of n − 1 then double each part and add two 1's.
-
If 2n = 2k then b(2n) = b(n) + 1. This is because b(2k − 1 − 1) = 0, as the only superbinary partition of 2k − 1 − 1 is [1, 2, 4, ..., 2k − 2] which is not reducible to a power of BIN. Therefore a sdb partition of 2k is either a power of BIN or some power of BIN times some power of 2.
Conversely, given a sdb partition of 2k − 1, double each part to get a sdb partition of 2k. Finally add BIN^(2k − 1) to the set of sdb partitions generated this way. QED.
::: Dijkstra's fusc function generalized :::
Dijkstra's fusc function is not only an elegant way to compute Stern's diatomic array, it is a blueprint for a whole family of important sequences. Therefore it seems worthwhile to have a second look at the structure of this function and to generalize it. Here is my suggestion. Meaning and use should become clear from the examples given below.
SternDijkstra := proc(L, p, n) local k, i, len, M;
len := nops(L); if len < 2 then RETURN("Error") fi;
if p < 1 or p > len then RETURN("Error") fi;
M := L; k := n;
while k > 0 do
M[1+(k mod len)] := add(M[i], i=1..len);
k := iquo(k, len);
od; op(p, M) end:
The first parameter L is an arbitrary list with at least two members, the second parameter is the projection p under the constraint 1 ≤ p ≤ length(L) and the third parameter is the index of the term n ≥ 0. We will call the pair of parameters to the Stern-Dijkstra function (L, p) the type of the array.
seq(SternDijkstra([0,1],1,n), n=0..32); seq(SternDijkstra([1,0],2,n), n=0..32); 0, 0, 1, 0, 2, 1, 1, 0, 3, 2, 3, 1, 2, 1, 0, 1, 1, 2, 1, 3, 2, 3, 1, 4, 3, 5, 2, 5,
Well, as every child knows, these are the lusc and fusc sequences, which plant beautiful trees. However, what a forest is planted form the sequences below?
seq(SternDijkstra([0,0,1],1,n), n=0..32); seq(SternDijkstra([0,1,0],2,n), n=0..32); seq(SternDijkstra([1,0,0],3,n), n=0..32); 0, 0, 0, 1, 0, 0, 1, 0, 0, 2, 2, 1, 1, 0, 0, 1, 1, 1, 1, 2, 1, 2, 1, 1, 1, 3, 2, 4, 3, 1, 3, 4, 0, 0, 1, 0, 0, 1, 1, 2, 2, 0, 0, 1, 0, 0, 1, 1,
[x, y, z], [x, x+y+z, z], [x, y, x+y+z], [x+y+z, x+2y+2z, z], [x, 2x+y+2z, z], [x, 2x+2y+z, x+y+z], [x+y+z, y, x+2y+2z], [x, x+y+z, 2x+y+2z], [x, y, 2x+2y+z], [x+2y+2z, x+3y+3z, z], [2x+y+2z, 3x+2y+4z, z], [2x+2y+z, 3x+4y+2z, x+y+z], [x+y+z, 2x+3y+4z, z], [x, 3x+y+3z, z], [x, 4x+3y+2z, x+y+z], [x+y+z, 2x+4y+3z, x+2y+2z], ...
::: Stern Matrices :::
SDVect := proc(L, n) local k, i, len, M;
len := nops(L); if len < 2 then RETURN("Error") fi;
M := L; k := n;
while k > 0 do
M[1+(k mod len)] := add(M[i], i=1..len);
k := iquo(k, len);
od; M end:
SDMat := proc(n, dim) linalg[matrix](
[seq(SDVect([seq(`if`(j=i,1,0),j=1..dim)],n),i=1..dim)]) end:
SDMatTree := proc(n, dim) local i, R, j, k;
for i from 0 to n-1 do
R := add(dim^j, j=0..i-1)..add(dim^j, j=0..i)-1:
print(seq(SDMat(k,dim),k=R));
od end:
print(`Binary tree of Stern matrices of dim 2`); SDMatTree(3,2); print(`Ternary tree of Stern matrices of dim 3`); SDMatTree(3,3);

Do you see Stern's diatomic array? Do you see the L-tree? (Look at the second column of the Stern matrices of dim 2.) What is the determinant of all these matrices? Stern matrices are a straightforward generalization of all the notions considered above. An account on this topic will appear elsewhere.
::: Ludwig Wittgenstein and unexpected conclusions :::
Prof. Stanley asked for examples of unexpected conclusions. However, what is an unexpected conclusion? This is a philosophical question, not a mathematical one.
In his Bemerkungen über die Grundlagen der Mathematik Wittgenstein argues that there are two types of unexpected conclusions: One type derives from the representation and the other from the facts. Wittgenstein claims that in mathematics there are no real surprises in the factual sense, it is only our lack of understanding which makes some conclusions 'unexpected'. In the long run, when our understanding deepens, all conclusions will become evident and trivial. (See: Felix Mühlhölzer: Wittgenstein and Surprises in Mathematics, in: Wittgenstein und die Zukunft der Philosophie, Wien 2002.) Günther Ziegler seems to disagree with Wittgenstein's view on the ground that there is no and there will never be a final understanding of mathematics (which would eliminate unexpected conclusions) (G. Ziegler, Darf ich Zahlen?, Piper, München, 2010).
An example for a surprise which comes from the 'representation' is at the end of the second section above where I point to the magic/miracle representation of the L-tree (which is Moshe Newman's generator of the Calkin-Wilf sequence with a different start condition — see Aigner and Ziegler, Proofs from THE BOOK, third ed.) On the other hand, I believe that the connection between partitions of integers and the enumerations generated by the generalized fusc function or by the Stern matrices will lead to a better understanding and then the conclusion, seen in this boarder context, will no longer look unexpected.
::: New sequences for the OEIS :::
Based on the above considerations I submitted the following sequences to OEIS.
|
|||||||||||||||||||||||||
|
|||||||||||||||||||||||||
|
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
KEYWORDS: Stern's diatomic array, Dijkstra's fusc function, Stern-Brocot tree, Calkin-Wilf tree, L-tree, Stern matrices,
hyperbinary representation, superbinary partition, superduperbinary partition, unexpected conclusion
SEQUENCES: OEIS A174980, OEIS A174981, OEIS A002487.
Copyright Peter Luschny, 2010. This article was written online on my
user page of the OEIS-wiki.
License: Creative Commons Attribution-ShareAlike 3.0 Unported License.